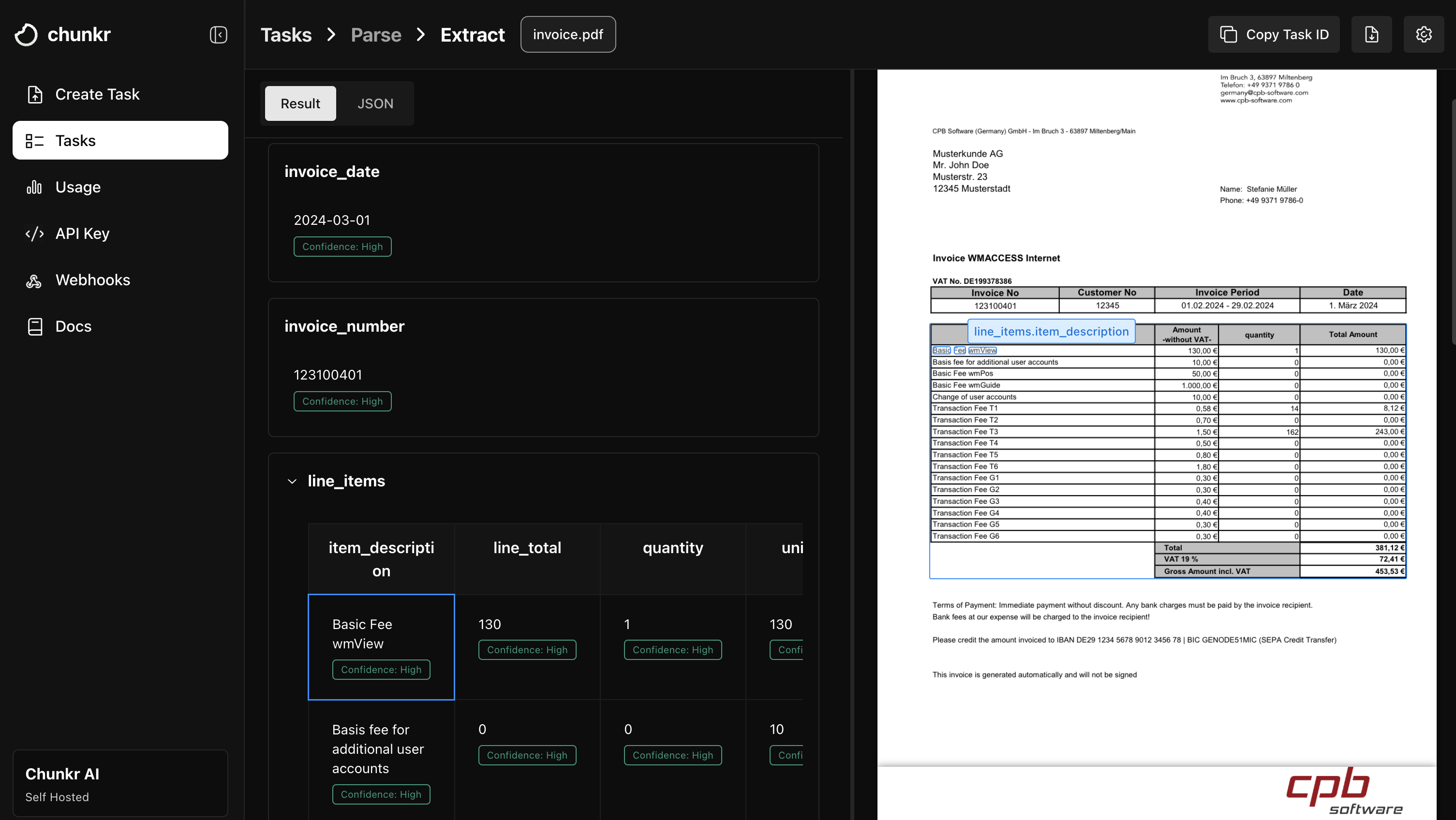
Key Features
- Schema-driven extraction: Define your exact data structure using JSON Schema and get perfectly formatted results.
- Granular citations: Every extracted value includes precise source references to the original document location.
- Confidence scoring: Built-in confidence metrics for each extracted field to assess reliability.
- Flexible input options: Works with existing parse tasks, raw documents, or remote URLs.
- Intelligent field mapping: Automatically identifies and maps document content to your schema fields.
How It Works
- Input Processing: Extract accepts either a raw document (URL, file upload, or base64) or a reference to an existing parse task.
- Schema Analysis: Your JSON schema is analyzed to understand the target data structure and field requirements.
- Intelligent Extraction: The system maps document content to your schema fields using AI.
- Citation & Scoring: Each extracted value is annotated with source citations and confidence.
- Structured Output: Returns your data in the exact schema format with enriched metadata.
Make a JSON Schema
Use Pydantic or Zod to define your schema, then pass the generated JSON schema to Extract.Input Options
- From a URL, a local upload using
client.files.create, base64, or from an existing parse task ID.
Advanced Configuration
Advanced Configuration
Extract supports all Parse configuration options when processing raw documents, plus extraction-specific settings:
Extraction Configuration
- Schema (
schema): Your JSON Schema definition that describes the target data structure. Required field. - System Prompt (
system_prompt): Customize the LLM prompt for extraction. Default: “You are an expert at structured data extraction. You will be given parsed text from a document and should convert it into the given structure.” - Task Expiration (
expires_in): Set automatic cleanup time in seconds for completed tasks.
Best Practices
- Schema Design: Create clear, well-structured schemas with descriptive field names to improve extraction accuracy.
- Type Specificity: Use appropriate JSON Schema types (string, number, boolean, array, object) and formats (date, email, uri) for better results.
- Include Field Descriptions: Use Pydantic’s
Field(description="...")or Zod’s.describe()to provide context. - Parse Task Reuse: When extracting multiple schemas from the same document, parse once and reference the task ID for efficiency.
- Citation Verification: Use the provided citations to build audit trails and allow users to verify extracted data against source documents.